AMD Bulldozer: Leitfaden für Software-Entwickler erschienen
AMD hat den "Software Optimization Guide" für die CPU-Familie 15h mit der kommenden Bulldozer-Mikroarchitektur veröffentlicht.

(Bild: AMD)
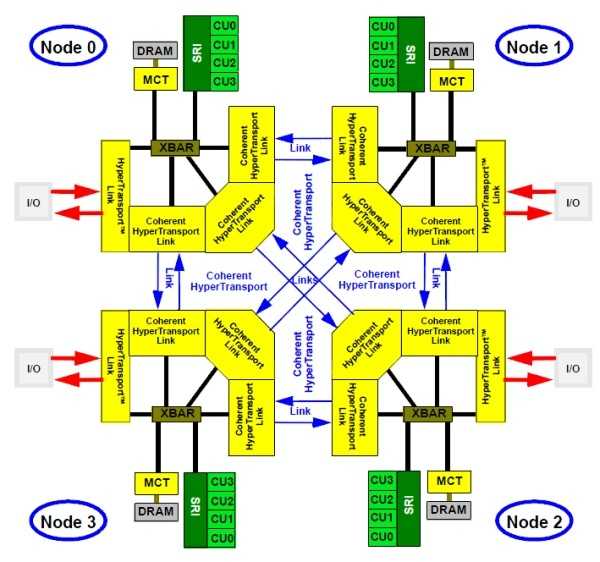
Auf der AMD-Webseite steht seit einigen Tagen der "Software Optimization Guide for AMD Family 15h Processors" zum Download bereit [1] (PDF-Datei). Der Leitfaden ist für Programmierer gedacht, deren Software die neuen Möglichkeiten der kommenden Bulldozer-Mikroarchitektur [2] ausreizen soll: Etwa Advanced Vector Extensions (AVX), Load-Execute-Befehle für Gleitkomma-(Floating-Point-) oder Ganzzahl-(Integer-)Operanden, Fused Multiply-Accumulate (FMAC) und viele mehr. Daneben beschreibt der Leitfaden auch Details der Bulldozer-Prozessoren, die als Zambezi alias FX [3] (4000, 6000, 8000) für AM3+-Mainboards [4] sowie in den Server-Versionen Valencia und Interlagos für C32- und G34-Boards kommen werden.
(Bild: AMD)
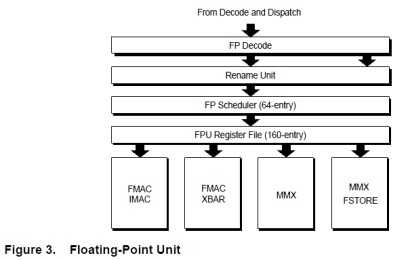
Laut dem AMD-Dokument enthalten (die ersten) Bulldozer-Prozessoren jeweils vier Compute Units, die wiederum je zwei (Integer-)Cores sowie eine Gleitkomma-Einheit (Floating-Point Unit, FPU) besitzen. Letztere besteht aus zwei 128-Bit-FMAC-Einheiten, die pro Taktschritt aber auch einen einzelnen 256-Bit-(AVX-)Befehl ausführen können. Zudem besitzt jede 128-Bit-FMAC auch eine IMAC-Einheit für ganze Zahlen.
AMD veröffentlicht in dem Dokument auch eine Rangliste der wichtigsten Verbesserungen, die Bulldozer bringt.
| Optimierungen nach Rangfolge | |
| Rang | Bezeichmung |
| 1 | Load-Execute Instructions for Floating-Point or Integer Operands |
| 2 | Write-Combining |
| 3 | Branches That Depend on Random Data |
| 4 | Loop Unrolling |
| 5 | Pointer Arithmetic in Loops |
| 6 | Explicit Load Instructions |
| 7 | Reuse of Dead Registers |
| 8 | ccNUMA Optimizations |
| 9 | Multithreading |
| 10 | Prefetch and Streaming Instructions |
| 11 | Memory and String Routines |
| 12 | Floating-Point Scalar Conversions |
Demnach verspricht AMD durch die Load-Execute-Befehle, die ein Datum einlesen und sofort verarbeiten, besonders große Geschwindigkeitsvorteile. Sie gibt es auch für SIMD-Befehle und sollen dort wiederum vor allem bei "Misaligned"-Zugriffen unnötige Wartezeiten vermeiden. Durch den "dichter gepackten" Code sollen aber auch der Befehls-Cache und indirekt auch der FP-Scheduler effizienter arbeiten. (ciw [5])
URL dieses Artikels:
https://www.heise.de/-1225457
Links in diesem Artikel:
[1] http://www.google.de/url?sa=t&source=web&cd=1&ved=0CBkQFjAA&url=http%3A%2F%2Fsupport.amd.com%2Fus%2FProcessor_TechDocs%2F47414.pdf&ei=UuSiTZycLYqDOqi1zTQ&usg=AFQjCNEUXGca0MVpihcs0cAb_oqfO5c0OA
[2] https://www.heise.de/news/ISSCC-Weitere-Details-zum-Bulldozer-von-AMD-1195087.html
[3] https://www.heise.de/news/AMD-Athlon-und-Phenom-ade-1200314.html
[4] https://www.heise.de/news/AMD-Neues-von-Bulldozer-und-Llano-1210809.html
[5] mailto:ciw@ct.de
Copyright © 2011 Heise Medien